


Inspiration
After having shared a class with a peer with motor neuron disability (ALS) in elementary/primary school, we realized the how diseases of this category can impair day to day life, especially in the classroom. According to a study in Lancet over 330K people globally had a motor neuron disease in 2016. The authors write, "Motor neuron diseases have low prevalence and incidence, but cause severe disability." We have witnessed this ourselves. We aims to assist people who lack upper body mobility and speech to more dynamically communicate (ALS, Locked-in Syndrome.)
What it does
Our software/hardware platform, Visual-Ed, uses langchain to provide smart conversation suggestions for the classroom enviroment. We display various suggestions at once and use an audio transcription to describe the current suggestion to the user. These suggestions can be selected by the user via eye movements due to a custom computer vision algorithm running on RaspberryPI. Eye movements are translated into actions, which generates text-to-speech that the teacher and students in the classroom can hear, allowing the student to naturally participate in the classroom environment.
How we built it / Technical Description
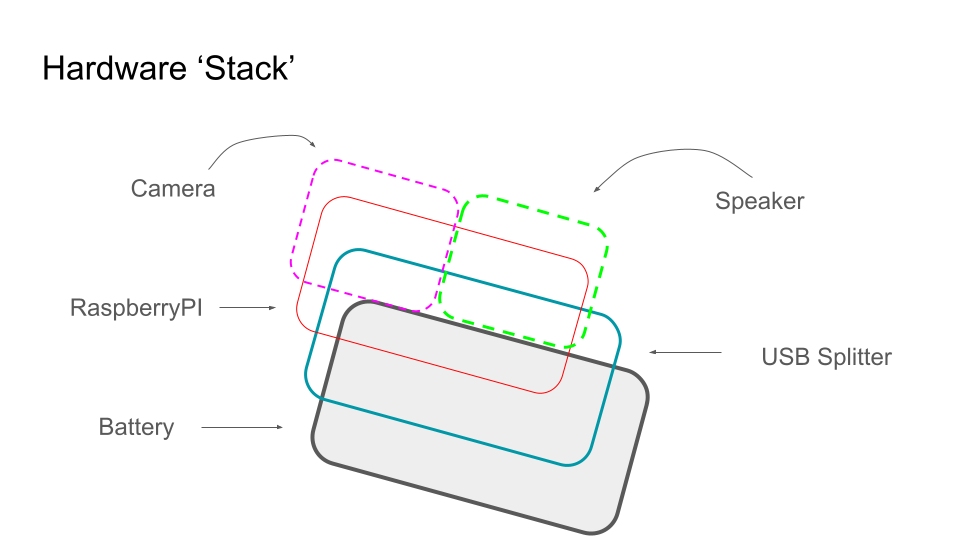
Our hardware is powered by a RaspberryPI. We pygame for the UI, and langchain for the smart text generation. We use an ElevenLabs text to speech model to generate audio. Our algorithm is built on top OpenCV. It works as follows:
- We first crop the native webcam resolution to a lower resolution for performance
- We use a harr cascade detector to find bounding boxes for faces
- Given the bounding box options, we use a scoring system to choose the most plausible face (not someone else's face in the background) to reduce uncertainty
- We apply a first pass of a kalman filter on this bounding box (frame) for stability
- The frame is then cropped. We select eye candidates based on the aspect ratio of the face.
- Using a term that biases the system towards selecting candidates in the upper portion of the face, we then run a Hough Cascade to filter candidates. We assign weights and us an adaptive grayscale threshold to select final candidates. A second kalman filter pass is made.
- Equalization is applied to the eyes and the image is inverted
- Shape and contour detection isolates the eye center and based on that we calculate the density of white pixels to determine if the user is looking at the camera or not. We apply these results per each eye and average the results.
Challenges we ran into
Lots of computer vision challenges... Lots of bug fixing on PI (code would run on our machines but not on the pi due to version differences and other nuanced factors).
Accomplishments that we're proud of
We are proud of the volume of work accomplished as well as the potential deep impact of our concept. We were extremely proud and excited to see all the various components of our project come together in the final hours of the hackathon!
What we learned
We learned to better coordinate as a team throughout the CI-CD process, especially with regards to having to share the hardware during testing. A huge lesson we learned is that we should merge early to ensure the barebones methods and building blocks work together as expected, so that development when the software complexity increases is more likely to be streamlines.
What's next for Visual-Ed
Refine the various features, including not only software but also hardware. We also hope to add features such as,
- Realtime classroom transcription (and feed this into our model)
- Pre-entered class information (syllabus, course material
Built With
- computervision
- gpt-3.5
- kalmanfilter
- langchain
- machine-learning
- opencv
- pygame
- python
- raspberrypi

Log in or sign up for Devpost to join the conversation.